OpenAI推出SearchGPT没几天,开源版本也来了。
港中文MMLab、上海AI Lab、腾讯团队简易实现了Vision Search Assistant,模型设计简单,只要两张RTX3090就可复现。

Vision Search Assistant(VSA)以视觉语言模型(VLM)为基础,巧妙地将Web搜索能力融入其中,让VLM内部的知识得到实时更新,使其更加灵活和智能。
目前,VSA已经针对通用图像进行了实验,可视化和量化结果良好。但不同类别的图像各具特色,还可以针对不同种类的图像(比如表格、医学等)构建出更为特定的VSA应用。
更令人振奋的是,VSA的潜力并不仅限于图像处理。还有更广阔的可探索空间,比如视频、3D模型和声音等领域,期待能将多模态研究推向新的高度。

让VLM处理未见过的图像和新概念
大型语言模型(LLM)的出现让人类可以利用模型的强大零样本问答能力来获取陌生知识。
在此基础上,检索增强生成(RAG)等技术进一步提高了LLM在知识密集型、开放域问答任务中的表现。然而,VLM在面对未见过的图像和新概念时,它们往往不能利用好来自互联网的最新多模态知识。
现有的 Web Agent主要依赖于对用户问题的检索,并总结检索返回的HTML文本内容,因此它们在处理涉及图像或其他视觉内容的任务时存在明显的局限性,即视觉信息被忽视或处理不充分。
为了解决这一问题,团队提出了Vision Search Assistant。Vision Search Assistant以VLM模型为基础,能够回答有关未见过的图像或新概念的问题,其行为类似人类在互联网上进行搜索并解决问题的过程,包括:
- 理解查询
- 决定应该关注图像中的哪些对象并推断对象之间的相关性
- 逐对象生成查询文本
- 根据查询文本和推断出的相关性分析搜索引擎返回的内容
- 判断获得的视觉和文本信息是否足以生成答案,或者它应该迭代和改进上述过程
- 结合检索结果,回答用户的问题
视觉内容描述
视觉内容描述模块被用来提取图像中对象级的描述和对象之间的相关性,其流程如下图所示。
首先利用开放域的检测模型来获取值得关注的图像区域。紧接着对每一个检测到的区域,使用VLM获取对象级的文本描述。
最后,为了更全面地表达视觉内容,利用VLM进一步关联不同的视觉区域以获得不同对象的更精确描述。

具体地,令用户输入图片为 ,用户的问题为 。可通过一个开放域的检测模型 获取 个感兴趣的区域:
然后利用预训练的VLM模型 分别描述这 个区域的视觉内容:
为了让不同区域的信息关联起来,提高描述的精度,可将区域 与其它区域 的描述拼接,让VLM对区域 的描述进行矫正:
至此,从用户输入获得了与之高度相关的 个视觉区域的精确描述 。
Web知识搜索:“搜索链”
Web知识搜索的核心是名为“搜索链”的迭代算法,旨在获取相关视觉描述的综合性的Web知识,其流程如下图所示。

在Vision Search Assistant中利用LLM来生成与答案相关的子问题,这一LLM被称为“Planing Agent”。搜索引擎返回的页面会被同样的LLM分析、选择和总结,被称为“Searching Agent”。通过这种方式,可以获得与视觉内容相关的Web知识。
具体地,由于搜索是对每个区域的视觉内容描述分别进行的,因此以区域 为例,并省略这个上标,即 。该模块中使用同一个LLM模型 构建决策智能体(Planning Agent)和搜索智能体(Searching Agent)。决策智能体控制整个搜索链的流程,搜索智能体与搜索引擎交互,筛选、总结网页信息。
以第一轮迭代为例,决策智能体将问题 拆分成 个搜索子问题 并交由搜索智能体处理。搜索智能体会将每一个 交付搜索引擎,得到页面集合 。搜索引擎会阅读页面摘要并选择与问题最相关的页面集合(下标集为 ),具体方法如下:
对于这些被选中的页面,搜索智能体会详细阅读其内容,并进行总结:
最终,所有 个子问题的总结输送给决策智能体,决策智能体总结得到第一轮迭代后的Web知识:
重复进行上述迭代过程 次,或是决策智能体认为当前的Web知识已足矣回应原问题时,搜索链停止,得到最终的Web知识 。
协同生成
最终基于原始图像 、视觉描述 、Web知识 ,利用VLM回答用户的问题 ,其流程如下图所示。具体而言,最终的回答 为:

实验结果
开放集问答可视化对比
下图中比较了新事件(前两行)和新图像(后两行)的开放集问答结果。
将Vision Search Assistant和Qwen2-VL-72B以及InternVL2-76B进行了比较,不难发现,Vision Search Assistant 擅长生成更新、更准确、更详细的结果。
例如,在第一个样例中,Vision Search Assistant对2024年Tesla公司的情况进行了总结,而Qwen2-VL局限于2023年的信息,InternVL2明确表示无法提供该公司的实时情况。

开放集问答评估
在开放集问答评估中,总共通过10位人类专家进行了比较评估,评估内容涉及7月15日至9月25日期间从新闻中收集的100个图文对,涵盖新颖图像和事件的所有领域。
人类专家从真实性、相关性和支持性三个关键维度进行了评估。
如下图所示,与Perplexity.ai Pro和GPT-4-Web相比,Vision Search Assistant在所有三个维度上都表现出色。

事实性:Vision Search Assistant得分为68%,优于Perplexity.ai Pro(14%)和 GPT-4-Web(18%)。这一显著领先表明,Vision Search Assistant 始终提供更准确、更基于事实的答案。
相关性:Vision Search Assistant 的相关性得分为80%,在提供高度相关的答案方面表现出显著优势。相比之下,Perplexity.ai Pro和GPT-4-Web分别达到11%和9%,显示出在保持网络搜索时效性方面存在显著差距。
支持性:Vision Search Assistant在为其响应提供充分证据和理由方面也优于其他模型,支持性得分为63%。Perplexity.ai Pro和GPT-4-Web分别以19%和24%的得分落后。这些结果凸显了Vision Search Assistant 在开放集任务中的卓越表现,特别是在提供全面、相关且得到良好支持的答案方面,使其成为处理新图像和事件的有效方法。
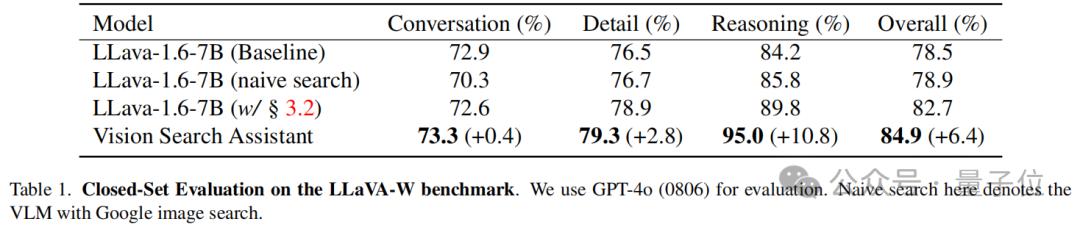
封闭集问答评估
在LLaVA W基准进行闭集评估,其中包含60个问题,涉及VLM在野外的对话、细节和推理能力。
使用GPT-4o(0806)模型进行评估,使用LLaVA-1.6-7B作为基线模型,该模型在两种模式下进行了评估:标准模式和使用简单Google图片搜索组件的“朴素搜索”模式。
此外还评估了LLaVA-1.6-7B的增强版本,该版本配备搜索链模块。
如下表所示,Vision Search Assistant在所有类别中均表现出最强的性能。具体而言,它在对话类别中获得了73.3%的得分,与LLaVA模型相比略有提升,提升幅度为+0.4%。在细节类别中,Vision Search Assistant以79.3%的得分脱颖而出,比表现最好的LLaVA变体高出 +2.8%。
在推理方面,VSA方法比表现最佳的LLaVA模型高出+10.8%。这表明Vision Search Assistant对视觉和文本搜索的高级集成极大地增强了其推理能力。
Vision Search Assistant的整体性能为84.9%,比基线模型提高+6.4%。这表明Vision Search Assistant在对话和推理任务中都表现出色,使其在野外问答能力方面具有明显优势。
论文:https://arxiv.org/abs/2410.21220主页:https://cnzzx.github.io/VSA/代码:https://github.com/cnzzx/VSA
本文来自微信公众号“量子位”,作者:VSA团队,aigpt6经授权发布。
相关文章

 粤ICP备2024279727
粤ICP备2024279727